



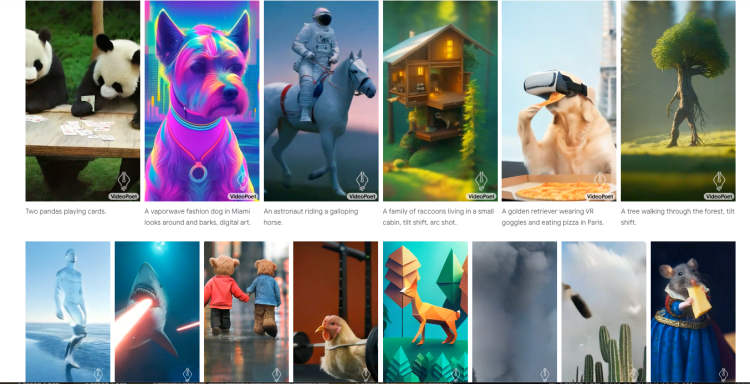
Just yesterday, Google Research showcased their latest achievement in the field of AI with VideoPoet. This innovative large language model (LLM) developed by a team of 31 researchers demonstrates Google’s dedication to improving video generation tasks.
Revolutionizing Video Generation
Unlike existing models that rely on diffusion-based methods, VideoPoet breaks new ground by utilizing a different approach. Instead of using the popular Stable Diffusion open source image/video generating AI, the Google Research team opted for an LLM based on the transformer architecture. Traditionally used for text and code generation, the transformer architecture proved to be highly effective in training the model to generate videos.
The VideoPoet LLM was extensively pre-trained on an extensive dataset of 270 million videos and over 1 billion text-and-image pairs sourced from the public internet and other reliable sources. This preparatory phase involved transforming the data into text embeddings, visual tokens, and audio tokens to condition the AI model.
Next-Level Video Generation
The results of Google’s research are nothing short of astounding. VideoPoet surpasses even the state-of-the-art consumer-facing video generation models like Runway and Pika. It overcomes the limitations of current diffusion-based AIs, which often struggle with maintaining coherence and quality in longer video clips.
“One of the current bottlenecks in video generation is in the ability to produce coherent large motions. In many cases, even the current leading models either generate small motion or, when producing larger motions, exhibit noticeable artifacts.” – Dan Kondratyuk and David Ross, Google Research team
VideoPoet distinguishes itself by generating larger and more consistent motion across 16-frame videos. It excels in simulating various camera motions, visual and aesthetic styles, and even creating new audio to complement the video. Moreover, VideoPoet seamlessly handles different inputs such as text, images, and videos to serve as prompts.
By encompassing all these video generation capabilities within a single LLM, VideoPoet eliminates the need for multiple specialized components, providing an all-in-one solution for video creation.
Human Preference and Future Scope
According to human raters surveyed by the Google Research team, VideoPoet outperformed competing models in terms of following prompts accurately and delivering more captivating motion. Video clips generated by VideoPoet were rated as superior by a significant margin.
“On average people selected 24–35% of examples from VideoPoet as following prompts better than a competing model vs. 8–11% for competing models. Raters also preferred 41–54% of examples from VideoPoet for more interesting motion than 11–21% for other models.”
Google Research has also optimized VideoPoet to produce videos in portrait orientation by default, catering to the rising demand for vertical videos in the mobile video marketplace.
As for the future, Google Research aims to expand VideoPoet’s capabilities to support “any-to-any” generation tasks, such as text-to-audio and audio-to-video. This ambitious vision demonstrates Google’s commitment to pushing the boundaries of video and audio generation.
However, one limitation remains: VideoPoet is currently unavailable for public usage. Although Google has not provided a specific timeline, they are working towards making it accessible to the wider audience.



